
Chapter 4 Data
In the previous chapters, we learned to share our materials through the Open Science Framework (OSF) and to organize all our files in a well structured and documented project.
In this chapter, we focus on data. In particular, in Section 4.1 we provide main guidelines regarding how to organize data inside our project and, in Section 4.2, we discuss main issues related to sharing data.
4.1 Organizing Data
Ideally, we want to store all the data relevant to our project in a dedicated directory (e.g., data/). These files should be considered read-only and, in the case of data that required some preprocessing, it is recommended to include also the original raw version of the data or provide a link to retrieve it.
However, storing the data and organising it efficiently is just part of the job. We also need to provide a detailed description with all the information to allow other colleagues (aka the future us) to understand what the data contain. We do not want to save and share useless files full of 0-1 values, right?
Let’s discuss how to organize and document our data together with other useful recommendations.
4.1.1 Data Structure
There are many data formats depending on the specific data type (e.g., questionnaires, brain imaging, ERP study, conversations, etc.) and there are often no common standards. Therefore, how to manage and organize data can vary according to the specific case and needs. However, as a general case, we can consider tabular data, that is, data organized in columns and rows.
Tabular data can be structured according to the wide format or the long format.
- Wide Format. Each variable value is recorded in a separate column.
Table 4.1: Wide Format Name Sex Age Pre Post Alice F 24 … … Bob M 21 … … Carl M 23 … … - Long Format. Multiple variables can be recorded using a column to indicate the name of the measured variable and another column for the measured values.
Table 4.2: Long Format Name Sex Age Time Value Alice F 24 Pre … Alice F 24 Post … Bob M 21 Pre … Bob M 21 Post … Carl M 23 Pre … Carl M 23 Post …
Depending on our specific needs, we may choose a wide or a long format to represent our data. Usually, the long format is the preferred data format, as it is required in most analyses. However, there is an important drawback when using the long format, that is, memory inefficiency.
In general, in a long format dataset, values are unique for each row only for a few columns, whereas for all the other columns the same values are (unnecessarily) repeated multiple times. The Long Format is an inefficient way to store our data.
In the case of small datasets, this does not make a big difference and we can safely continue to store the data using the long format as is the preferred data format in most analyses. When we need to deal with large datasets, however, memory may become a relevant issue. In these cases, we need to find a more efficient way to store our data. For example, we can use the relational model to organize our data.
Relational Model. Instead of a single large table, the relational model organizes the data more efficiently by using multiple tables. Now, how can we use multiple tables to organize our data more efficiently? To clarify this process, let’s consider the data presented in the table above. We have information about participants (i.e., Name, Sex, and Age) and two measures (i.e., Pre and Post) on some outcomes of interest in our study. Using the long data format, participants’ information is (unnecessarily) repeated multiple times. Following a relational model, we can create two separate tables, one for the participants’ information and the other for the study measures. In this way, we do not repeat the same information multiple times optimizing the memory required to store our data.
Table 4.3: Subjects ID Name Sex Age 1 Alice F 24 2 Bob M 21 3 Carl M 23 Table 4.3: Study ID Subject_ID Time Value 1 1 Pre … 2 1 Post … 3 2 Pre … 4 2 Post … 5 3 Pre … 6 3 Post … But, how should we read these tables? Note that each table has a column
IDwith the unique identifier for each row. These IDs are used to define the relational structure between different tables. For example, in our case, the table Study has a columnSubject_IDthat indicates the subject ID for that specific row. Matching theSubject_IDvalue in the Study table with theIDcolumn in the Subjects table, we can retrieve all the participants’ information from a specific row.This matching operation is usually defined as a JOIN operation and allows us to reconstruct our data in the desired format starting from separate tables.
If you have used SQL before, you are already familiar with relational databases and join operations. At first, these concepts may seem very complicated. In reality, as soon as we familiarize ourselves with all the technical terms, everything becomes very easy and intuitive. So do not be scared by buzz words such as “primary-key”, “foreign-key”, “left-join”, “inner-join”, or other jargon. You will quickly master all of them.
Most programming languages provide dedicated libraries and tutorials to execute all these operations. For example, if working with R consider https://r4ds.had.co.nz/relational-data.html.
4.1.2 Documentation
A dataset without documentation is like a sky without stars\(\ldots\) we can not see anything. We need to describe our data by providing details not only regarding all the variables but also about the data collection process or other information that could be relevant to properly interpret the data.
To document the data, we do not need anything fancy, a simple Markdown file is more than enough. An advantage of using Markdown files is that most online repositories automatically render Markdown files when navigating from the browser.
So, considering the data in the previous example, we could create the following data-README.md.
#----- data-README.md ----#
# Data README
## General Info
Details about the study/project, authors, License, or other relevant
information.
Description of the data collection process or links to the paper/external
documentation for further details.
## Details
The dataset `my-study.csv` is formed by n rows and k columns:
- `Name`. Character variable indicating the subject name
- `Sex`. Factor variable indicating the subject gender (levels are `"F"`
for females and `"M"` for males)
- `Age`. Numeric variable indicating subject age (in years)
- `Time`. Factor variable indicating measure time (levels are `"Pre"` and
`"Post"`)
- `Value`. Numeric variable indicating the outcome measure
- ...There are no strict rules about what we should include or not in our data README file. We are free to structure it according to our needs. As a generic recommendation, however, we should specify data general information about:
- Study/Project. Reference to the specific study or project.
- Authors. List of the authors with contact details of the corresponding author or the maintainer of the project.
- License. Specify under which license the data are released (see Section 4.2.3).
- Data Collection Process. Description of relevant aspects of the data collection or external links for further details.
Ideally, we should provide all the required details to allow other colleagues to understand the context in which data were collected and to evaluate their relevance for possible other uses (e.g., meta-analyses). We can also provide links to raw data if these are available elsewhere.
Considering the information about the dataset, we should provide the dimension of the dataset and a list with the details for each variable. In particular, we should indicate:
- Variable Name. The name of the variable as it is coded.
- Variable Type. The specific variable type (i.e., string, integer, numeric, logic, other)
- Variable Meaning. The description of what the values indicate.
- Variable Values. Information about the variable values. This could include a list of all the labels and their meaning (or the number of levels) for categorical variables; the range of allowed values for numeric variables; the unit of measurement or a description of how the variable was computed if relevant.
- Missing Values. Specify how missing values are coded or any other value used to indicate special conditions.
4.1.3 Data Good Practices
Finally, let’s consider two other general aspects regarding data that are important to take into account:
File Format. There are many possible file formats. However, an important distinction concerns proprietary format and open format (definitions adapted from the Open Data Handbook, see https://opendatahandbook.org).
Proprietary Format. Those formats owned and controlled by a specific company. These data formats require specific dedicated software to be read reliably and usually, we need to pay to use them. Note that the description of these formats may be confidential or unpublished, and can be changed by the company at any time. Common examples are XLS and XLSX formats used by Microsoft Excel.
Open Format. All those file formats that can be reliably used by at least one free/open-source software tool. A file in an open format guarantees that there are no restrictions or monetary fee to correctly read and use it. Common examples are the
RDAandRDSformats used internally by R.
We should avoid proprietary formats and always use open formats, instead. In particular, we should not use open formats related to specific software (even if is open-source), but prefer general text formats (e.g., CSV) that can be used easily by many tools.
Machine Readable. Data should be stored in a format that allows other researchers to easily use them. People saving tabular data in a PDF file would deserve to be punished in hell. Do they expect us to copy and paste all values by hand?
Character Encoding. All characters (i.e., letters, numbers and symbols) are stored in our machine as sequence bits (i.e., the fundamental unit of information that can assume binary values 0 or 1). Encoding refers to the specific process of converting different characters into their numerical representation. While decoding is the reverse operation.
There are different standards for different alphabets, so if we open a text file using the wrong decoding, characters can be confused with each other. Many issues typically arise with accented letters.
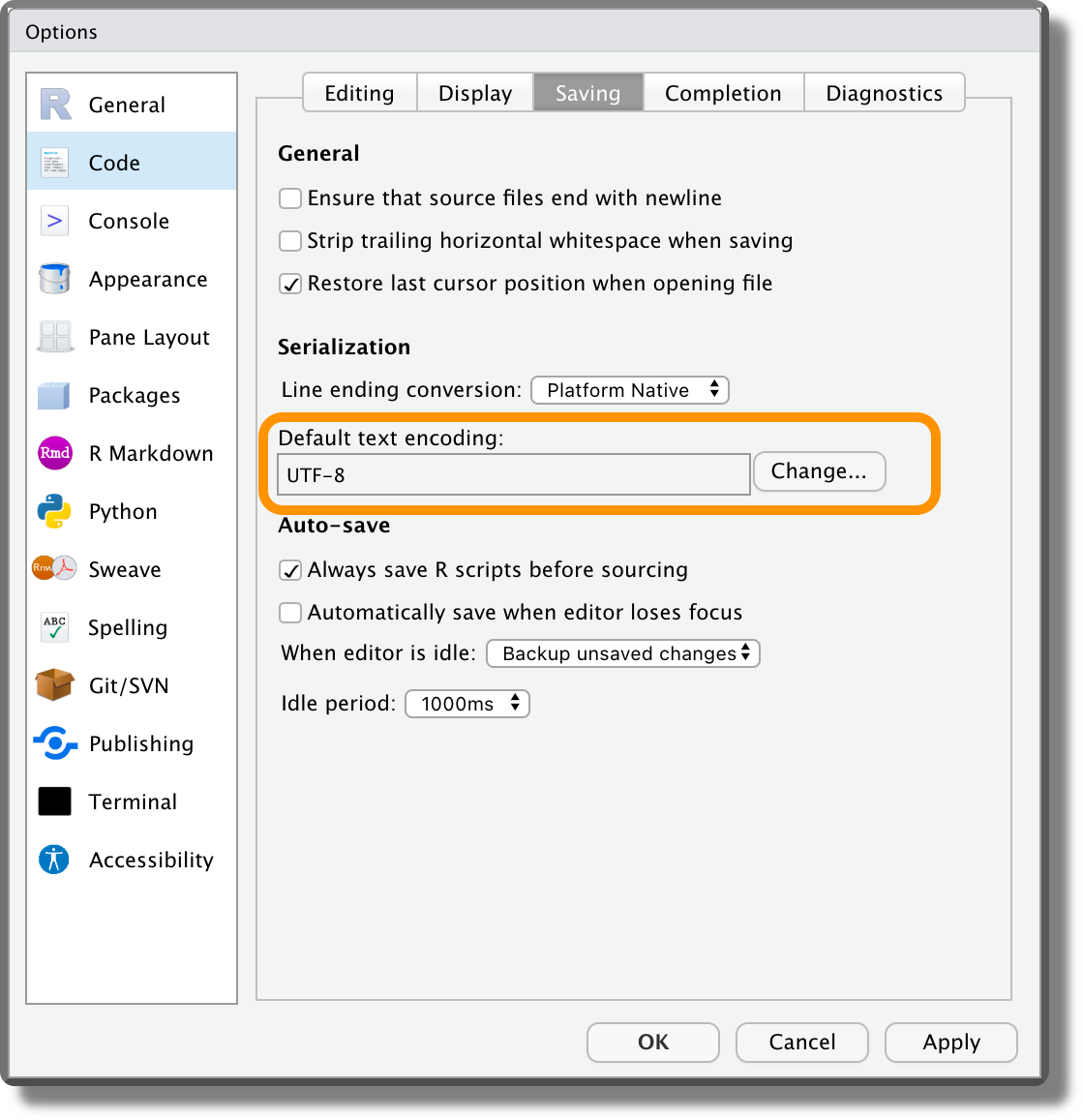
UTF-8 is becoming the standard method for encoding files, as it allows to encode efficiently all characters from any alphabet. We should always save our data and any other file using the UTF-8 encoding. If for some reason we need to use a different encoding, remember to explicitly state the used encoding. This will save our colleagues from lots of trouble.
From RStudio, we can set UTF-8 as default text encoding from “Tools > Global Options > Code > Saving”.
The Rawer the Better. We should share data in a format as raw as possible allowing other colleagues to reproduce the analysis from the very beginning.
4.2 Sharing Data
The most important part of our studies is not our conclusions but our data. Of course, this is a very provocative claim, but there is some truth in it. Making data available allows other researchers to build upon previous work leading to the efficient incremental development of the scientific field. For these reasons, we should always share our data.
Imagine we came up with a new idea. If we have access to many datasets relevant to the topic, we could immediately test our hypotheses. This would allow us to refine our hypotheses and properly design a new experiment to clarify possible issues. Wouldn’t this be an ideal process?
Of course, one of the main resistance to sharing data is that data collection is extremely costly in terms of time, effort and money. Therefore, we may feel reluctant to share something that cost us so much and from which others can take all the merits if they come up with a new finding. Unfortunately, in today’s hyper-competitive “publish or perish” world, the spotlight only shines on who comes with the new ideas neglecting the fundamental contribution of those who collected the data that made all this possible. Hopefully, in the future, the merit of both will be recognized.
Regarding this topic, there is a famous historical anecdote. Almost anyone knows or at least has heard Kepler’s name. Johannes Kepler (1571 – 1630) was a German astronomer and mathematician who discovered that the orbits of planets around the Sun are elliptical and not circular as previously thought. This was an exceptional claim that earned him eternal fame with Kepler’s laws of planetary motion (https://en.wikipedia.org/wiki/Kepler%27s_laws_of_planetary_motion). However, fewer people know the name of Brahe. Tycho Brahe (1546 - 1601) was a Danish astronomer, known for his accurate and comprehensive astronomical observations. Kepler became Brahe’s assistant and thanks to Brahe’s observational data was able to develop his theory about planetary motion. Of course, any researcher would like to become the next Kepler with an eternal law in our name, but who knows, we might as well as be remembered for our data. Do not waste the opportunity of being the next Brahe!
So, after this historical excursus, let’s go back to the present and discuss relevant aspects of sharing data.
4.2.1 When, Where, Who?
Let’s consider some common questions about sharing data:
When to Share?. From a user point of view, probably the best timing is when the reference article goes to press. In this way, we try to get the best out of our valuable data but we also make them available so other researchers can build upon our work.
We can also share data and materials in a private mode, granting access to selected people (e.g., reviewers) before the publication, and unlocking the public access in a second moment.
However, some restrictions can arise from the legal clauses of the research grants or other legal aspects. If we are not allowed to share the data, we should at least justify the reasons (e.g., privacy issues, national security secrets).
Where to Share?. We need to store materials in an online repository and provide the link to the repository and related research papers that are based on these materials.
Ideally, we will collect everything in a single place. However, we could also store them in multiple places, to get the advantage of services with appropriate features for specialized types of data or materials. In this case, we should choose a central hub and provide links to other repositories. Of course, this increases the effort required to organize and maintain the project.
There are many services that allow us to share our material and provide many useful features. For example:
Moreover, there could be dedicated services for specific scientific fields or data types.
With whom to share? Data need not be necessarily made available to everybody to meet open-science standards.
Many online services allow us to select with whom to share our data. For example, Databrary allows different Release Levels for sharing data: Private (data are available only to the research team); authorized users (data are available to authorized researchers and their affiliates); public (data are available openly to anyone).
 (
( (
( (
( (
( (
( (
(4.2.2 Legal Aspects
Specific legal restrictions related to data sharing change from state to state. Therefore, here we only discuss the general recommendation and we should always ensure to abide by our local legal restrictions.
Informed Consent and Permission to Share. Participants should be informed about the study (e.g. purposes, approval by an ethics committee), what the risks are, and their rights (e.g. to leave the study). We need both, participants’ consent to participate in the research study and participants’ permission to share their research data.
Note that these are two different things and the best practice for permission to share data is to seek it after the completion of research activities. This ensures that participants are fully aware of the study’s procedures and what they are being asked to share.
Data Subject to Privacy Rules. When sharing data we need to pay special attention to:
- Personal data is information making a person identifiable.
- Sensitive data are personal data revealing racial or ethnic origin, religious and philosophical beliefs, political opinions, labour union membership, health, sex life and sexual orientation, and genetic and biometric data.
- Legal data are another type of personal data on which put attention
- Other data such as private conversations, geolocalization, etc., also require special attention.
Data Anonymization. Pseudonymisation or removing any information that could be used to identify participants is necessary before sharing the data.
Geographical Restrictions. [TODO: check] The GDPR requires that all data collected on citizens must be either stored in the EU, so it is subject to European privacy laws, or within a jurisdiction that has similar levels of protection.
4.2.3 License
As discussed in Chapter 3.1.1.6, specifying a license is important to clarify under which conditions other colleagues can copy, share, and use our project. Without a license, our project is under exclusive copyright by default. Therefore, we always need to add a license to our project.
The same applies to data. In addition to the Creative Commons Licenses presented in Chapter 3.1.1.6, there are also other licenses specific for data/databases published by the Open Data Commons, part of the Open Knowledge Foundation.
A database right is a sui generis property right, that exists to recognise the investment that is made in compiling a database, even when this does not involve the “creative” aspect that is reflected by copyright (from Wikipedia; https://en.wikipedia.org/wiki/Database_right).
The main Open Data Commons Licenses are
- ODC-BY. Open Data Commons Attribution License requiring Attribution.
- ODbL. Open Data Commons Open Database License requiring Attribution and Share-alike.
- PDDL. Open Data Commons Public Domain Dedication and License dedicated to the Public Domain (all rights waived).
- DbCL. Database Content License requiring Attribution/Share-alike.
Note that Open Data Commons licenses distinguish between “database” and “content”. Why distinguish? Image a database of images\(\ldots\)When licensing data, you need to know if the content of the database is homogeneous in terms of the license, or not, and to license accordingly.
[TODO: ?? expand]
For all the details about licenses dedicated to open data and how to apply them, see https://opendefinition.org/licenses/.
4.2.4 Metadata
Finally, to really be open, data must be findable as well. All our effort will be wasted if no one can find our data. However, just sharing the links of an online repository could not be enough. We need to make our data findable by research engines for datasets such as Google Dataset Search (https://datasetsearch.research.google.com).
To do that, our data needs to be formatted according to a machine-readable format. Moreover, we need to provide the required metadata. Metadata is information about the data going with main data tables. In particular, we have:
- Data Dictionary: a document detailing the information provided by data (e.g. the type of data, the author);
- Codebook: if necessary, a document describing decoding rules for encoded data (e.g. 0=female / 1=male, Likert descriptors).
These documents are similar to what we described in Section 4.1.2. However, before we created human-readable reports, now we need to structure these files in a machine-readable format.
Two data formats that are machine-readable (but also fairly human-readable) are the eXtensible Markup Language (XML) and the JavaScript Object Notation (JSON) formats.
These topics are beyond the aim of the present chapter. However, the “Getting Started Creating Data Dictionaries: How to Create a Shareable Data Set” tutorial by Buchanan et al. (2021) provides a detailed guide to creating dictionaries and codebooks for sharing machine-readable data.
In particular, they cover the use of:
- JSON-Linked Data (JSON-LD), a format designed specifically for metadata.
- Schema.org (https://schema.org/), a collaborative, community activity with a mission to create, maintain, and promote schemas for structured data on the Internet.
The combination of JSON-LD and Schema.org allows the creation of machine-readable data optimized for search engines.
Relational Data
- Relational Data in R
https://r4ds.had.co.nz/relational-data.htm
Open Data
- Open Data Handbook
https://opendatahandbook.org/ - Google Dataset Search
https://datasetsearch.research.google.com/
Repository Platforms
- The Open Science Framework (OSF)
https://osf.io - GitHub
https://github.com - GitLab
https://gitlab.com - The Dataverse Project
https://dataverse.org - Databrary
https://nyu.databrary.org - Inter-university Consortium for Political and Social Research (ICPSR)
https://www.icpsr.umich.edu
License Open Data
- Database Rights
https://en.wikipedia.org/wiki/Database_right - Conformant License
https://opendefinition.org/licenses/
Metadata
- “Getting Started Creating Data Dictionaries: How to Create a Shareable Data Set” Buchanan et al. (2021)
https://doi.org/10.1177/2515245920928007 - Schema.org
https://schema.org/