[1] 3[1] 3[1] TRUEGli oggetti si possono creare e tramite il comando <- oppure =
[1] 3[1] 3[1] TRUEI nomi degli oggetti devono iniziare con una lettera!! NON “nome” = …ma nome = …
In R è possibile congiungere più relazioni per valutare una desiderata proposizione.
| Funzione | Nome | Esempio | Risulato |
|---|---|---|---|
& |
Congiunzione | x>25 & x<60 |
TRUE |
| |
Disgiunzione Inclusiva | x>25 | x>60 |
TRUE |
! |
Negazione | !(x<18) |
TRUE |
un valore: il valore dell’elemento che può essere di qualsiasi tipo ad esempio un numero o una serie di caratteri
un indice di posizione: un numero intero positivo che identifica la sua posizione all’interno del vettore.
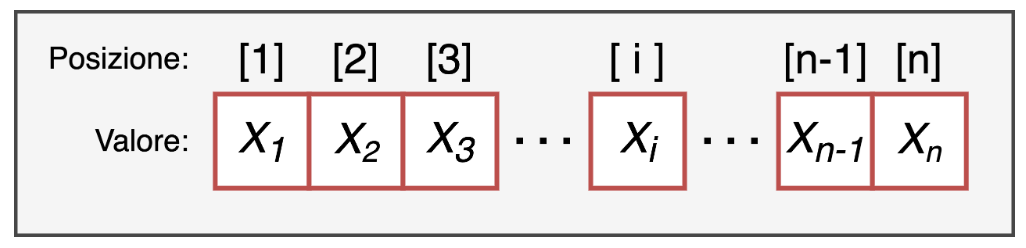
I vettori si possono creare attraverso il comando c(), indicando tra le parentesi i valori degli elementi nella sucessione desiderata e separati da una virgola.
num_vect = c(1,2,3,4)
# è possibile anche utilizzare la funzione seq()
num_vect_seq = seq(from = 1,to = 4, by = 1)
num_vect;num_vect_seq[1] 1 2 3 4[1] 1 2 3 4char_vect = c("R","R","R","ok")
# è possibile anche utilizzare la funzione rep()
char_vect_rep = c(rep("R", 3), "ok")
char_vect;char_vect_rep[1] "R" "R" "R" "ok"[1] "R" "R" "R" "ok"Un vettore deve esssere formato da elementi tutti dello stesso tipo!
Altrimenti si “rischia” che tutto venga trasformato a carattere.
Possiamo testare o convertire (quando possibile) la tipologia del vettore attraverso queste funzioni is. & as.
Possiamo selezionare, eliminare, estrarre elementi semplicemente usando l’indice di posizione tramite le parentesi quadre vettore[pos]
Allo stesso modo possiamo decidere di estrarre tutti gli elementi del vettore eccetto alcuni
Indicizzare con la posizione è l’aspetto più semplice e intuitivo. E’ possibile anche selezionare tramite valori TRUE e FALSE: possiamo estrarre elementi dal vettore basandoci su specifiche condizioni logiche
I fattori si possono creare sia convertendo un vettore character attraverso il comando as.factor() che creando esplicitamente un fattore attraverso il comando factor()
In pratica assegnano un’etichetta ad un valore numerico intero:
I fattori permettono di avere dei livelli levels() come metadati, a prescindere da quali siano effettivamente presenti nel vettore
[1] "ciao" "hello" "hola" [1] hello hello hola hola
Levels: ciao hello holaE’ possibile però eslcudere i livelli non più utili attraverso il comando droplevels()
E’ possibile anche rinominare i livelli del fattore
[1] hello hello ciao ciao hola hola
Levels: ciao hello hola# creo un altro fattore "my_fact_lev" identico a "my_fact"
my_fact_lev = my_fact
my_fact_lev == my_fact[1] TRUE TRUE TRUE TRUE TRUE TRUE# rinomino i livelli del fattore
levels(my_fact_lev) = c("italiano","inglese","spagnolo")
my_fact_lev[1] inglese inglese italiano italiano spagnolo spagnolo
Levels: italiano inglese spagnolo[1] hello hello ciao ciao hola hola
Levels: ciao hello holaE’ possibile sia riordinare che rinominare i livelli di un fattore attraverso la funzione factor()
[1] hello hello ciao ciao hola hola
Levels: ciao hello hola[1] 2 2 1 1 3 3[1] hello hello ciao ciao hola hola
Levels: hello ciao hola[1] 1 1 2 2 3 3new_fact2 = factor(my_fact, levels = c("hello","ciao","hola"),
labels = c("inglese","italiano","spagnolo"))
new_fact2[1] inglese inglese italiano italiano spagnolo spagnolo
Levels: inglese italiano spagnoloRicordate: l’argomento levels dentro la funzione factor() serve a riordinare i livelli del fattore, mentre la funzione levels() li rinomina non riordina!
Le liste sono strutture flessibili che possono contenere oggetti di tipo differente e di differenti dimensioni (ogni elemento può essere a sua volta una lista)
La lista pur essendo unidimensionale, si sviluppa in profondità
Primo Livello: lista
Secondo Livello: vettore numerico
Terzo Livello: numero intero
E’ possibile assegnare dei nomi agli elementi della lista…
… ed accerdervi chiamandoli per “nome” attraverso l’operatore $
Come per i vettori anche le liste hanno una lunghezza (lenght()) ed eventualmente dei nomi (names()). Il comando str() (struttura) è molto utile per le liste perchè fornisce una visione sulla struttura:
La differenza tra le parentesi quadre riguarda il fatto se vogliamo fare un subset della lista ottenendo un’altra lista oppure se vogliamo accedere direttamente all’elemento interno:
Se vogliamo selezionare più elementi (quindi fare un vero e proprio subset della lista) dobbiamo sempre usare le parentesi quadre singole:
Le liste hanno una struttura unidimensionale ma che si può sviluppare in profondità. Per selezionare elementi nested si possono concatenare più parentesi:
Le matrici sono una struttura dati bidimensionale (caratterizzate da 2 dimensioni dim() ) dove il numero di righe rappresenta la dimensione 1 e il numero di colonne la dimensione 2.
[,1] [,2] [,3] [,4] [,5]
[1,] 1 3 5 7 9
[2,] 2 4 6 8 10Possono contenere una sola tipologia di dati
Essendo bidimensionali, abbiamo bisogno di due indici di posizione (righe e colonne) per identificare un elemento
Possono essere viste come un insieme di singoli vettori
Il numero di righe e colonne non deve essere lo stesso necessariamente (matrice quadrata) ma il numero di righe deve essere compatibile con il vettore data:
Cosa fa R di default?
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9 [,1] [,2] [,3]
[1,] 1 2 1
[2,] 2 1 2
[3,] 1 2 1warnings: la funzione ci informa di qualcosa di potenzialmente problematico, ma (circa!!) tutto liscio
Per identificare uno o più elementi nella matrice abbiamo bisogno di indici/e di riga e/o colonna separati da virgola, sempre con le parentesi quadre: matrice[riga, colonna]
E’ possibile anche selezionare un’intera riga o colonna
Come per i vettori, anche in questo caso possiamo applicare l’indicizzazione logica:
I vettori si creano attraverso la funzione c() e possono essere concatenati tra loro sempre attraverso la stessa funzione:
Similarmente, le matrici possono essere unite tra loro attraverso i comandi cbind() e rowbind() :
Il dataframe è la struttura più “complessa”, utile e potente di R. Da un punto di vista intuitivo è un foglio excel mentre da un punto di vista di R è una tipologia di lista con alcune caratteristiche/restrizioni
Attraverso la funzione data.frame() è possibile creare un dataframe…
Il dataframe ha sia gli attributi della lista ovvero i names ma anche gli attributi della matrice ovvero le dimensioni (righe e colonne)
Si posso utlizzare sia le parentesi quadre [] che il simbolo del dollaro $
Una delle operazioni più comuni che dovrete affrontare sarà sicuramente quella di estrarre/valutare un sottoinsieme di valori presenti nel vostro dataset:
col1 col2 col3
1 1 a -0.4456488
2 2 b 0.8889884
3 3 c 0.4996634
4 4 d -0.7886895my_df[my_df$col1 > 1 & my_df$col1 < 4, ]
my_df[my_df$col1== 1, "col3"]
my_df[my_df$col1== 1, 3]
Ci sono anche dei modi alternativi e più compatti di indicizzare. Ad esempio usando la funzione subset():
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
25 4.8 3.4 1.9 0.2 setosa
45 5.1 3.8 1.9 0.4 setosaequivalente a:
E’ possibile anche selezionare colonne piuttosto che righe attraverso l’argomento select:
Possiamo anche combinare le due cose:
Sepal.Length Species
1 5.1 setosa
2 4.9 setosa
3 4.7 setosaequivalente a:
La maggiorparte delle volte vi troverete ad accedere alle variabili tramite l’operatore $. Questo comando può essere utilizzato anche per creare una nuova variabile…
'data.frame': 150 obs. of 6 variables:
$ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
$ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
$ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
$ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
$ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...
$ somma : num 8.6 7.9 7.9 7.7 8.6 9.3 8 8.4 7.3 8 ...https://etherpad.wikimedia.org/p/arca-corsoR