3.3_apply
*apply family
Immaginate di avere una lista di vettori, e di voler applicare la stessa funzione/i ad ogni elemento della lista:
applico manualmente la funzione selezionando gli elementi
ciclo
forche itera sugli elementi della lista e applica la funzione/i…
*apply family
Applichiamo media, mediana e std
*apply family
Funziona tutto! ma:
il for è molto laborioso da scrivere gli indici sia per la lista che per il vettore che stiamo popolando
dobbiamo pre-allocare delle variabili (per il motivo della velocità che dicevo)
8 righe di codice (per questo esempio semplice)
*apply family
In R è presente una famiglia di funzioni apply come lapply, sapply, etc. che permettono di ottenere lo stesso risultato in modo più conciso, rapido e semplice:
*apply family
apply( < lista > , < funzione > )
- Cosa può essere la lista?
lista
dataframe
vettore
- Cosa può essere la funzione?
base o importata da un pacchetto
custom
anonima
*apply family
Prima di analizzare l’*apply family, credo sia utile un ulteriore parallelismo con il ciclo for che abbiamo visto. apply non è altro che un ciclo for, leggermente semplificato.
*apply family - funzione custom
Possiamo utlizzare anche funzioni create da noi:
center_var = function(x){
x - mean(x)
}
my_list = list(
vec1 = runif(n = 10, min = 0, max = 1),
vec2 = runif(n = 10, min = 0, max = 1),
vec3 = runif(n = 10, min = 0, max = 1)
)
lapply(my_list, center_var)$vec1
[1] -0.32925173 -0.19082880 0.15370428 0.21454680 0.08290650 -0.06992764
[7] -0.09205525 -0.14301685 0.36358998 0.01033271
$vec2
[1] 0.407171782 -0.061425160 -0.233693446 -0.229665950 0.054355292
[6] -0.007424611 0.567966149 0.035132294 -0.303290868 -0.229125482
$vec3
[1] 0.076075118 -0.118903307 0.036839899 0.046388801 -0.011379043
[6] -0.029008392 0.004295505 0.372808293 -0.397392429 0.020275555*apply family - implicito vs. esplicito
Quindi come il ciclo for scritto come i in vec assegna al valore i un elemento per volta dell’oggetto vec, internamente le funzioni *apply prendono il primo elemento dell’oggetto in input (lista) e applicano direttamente la funzione che abbiamo scelto.
*apply family - funzione anonima
Una funzione anonima è una funzione non salvata in un oggetto ma scritta per essere eseguita direttamente, all’interno di altre funzioni che lo permettono:
$vec1
[1] -0.32925173 -0.19082880 0.15370428 0.21454680 0.08290650 -0.06992764
[7] -0.09205525 -0.14301685 0.36358998 0.01033271
$vec2
[1] 0.407171782 -0.061425160 -0.233693446 -0.229665950 0.054355292
[6] -0.007424611 0.567966149 0.035132294 -0.303290868 -0.229125482
$vec3
[1] 0.076075118 -0.118903307 0.036839899 0.046388801 -0.011379043
[6] -0.029008392 0.004295505 0.372808293 -0.397392429 0.020275555x è solo un placeholder (analogo di i) e può essere qualsiasi lettera o nome!
Tutte le tipologie di *apply
lapply(): la funzione di basesapply(): simplified-applytapply(): poco utilizzata, utile con i fattoriapply(): utile per i dataframe/matricimapply(): versione multivariata, utilizza più liste contemporaneamentevapply(): utilizzata dentro le funzioni e pacchetti
lapply
lapply sta per list-apply e restituisce sempre una lista, applicando la funzione ad ogni elemento della lista in input:
sapply
sapply sta per simplified-apply e (cerca) di restituire una versione più semplice di una lista, applicando la funzione ad ogni elemento della lista in input:
apply
apply funziona in modo specifico per dataframe o matrici, applicando una funzione alle righe o alle colonne:
apply
Applico a tutte le righe (1) la funzione mean:
Applico a tutte le colonne (2) la funzione mean:
tapply
tapply permette di applicare una funzione ad un vettore, dividendo questo vettore in base ad una variabile categoriale:
a b c
0.20722135 0.02627223 0.11147354 Qui dove INDEX è un vettore stringa o un fattore.
tapply
In questo caso calcoliamo la media per ogni categoria d’età:
# A tibble: 6 × 4
id age age_cat age_z
<dbl> <dbl> <chr> <dbl>
1 1 14 adolescente -1.63
2 2 30 giovane -0.164
3 3 26 giovane -0.530
4 4 33 adulto 0.110
5 5 45 adulto 1.21
6 6 20 giovane -1.08 adolescente adulto giovane
16.00000 39.88235 24.50000 vapply
vapply è una versione più solida delle precedenti dal punto di vista di programmazione. In pratica permette (e richiede) di specificare in anticipo la tipologia di dato che ci aspettiamo come risultato:
vec1 vec2 vec3
0.4572524 0.3213984 0.4586227 FUN.VALUE = numeric(length = 1): indica che ogni risultato è un singolo valore numerico.
mapply
mapply permette di gestire più liste contemporaneamente per scenari più complessi. Ad esempio vogliamo usare la funzione rnorm() e generare 4 con diverse medie e deviazioni stardard in combinazione:
medie = list(10, 20, 30, 40)
stds = list(1, 2, 3, 4)
mapply(function(x,y) rnorm(n = 5, mean = x, sd = y),
medie, stds, SIMPLIFY = FALSE)[[1]]
[1] 10.066647 10.379046 10.499784 9.217796 10.608312
[[2]]
[1] 20.96248 17.94844 17.87938 23.63231 17.78597
[[3]]
[1] 37.41181 35.30315 29.78616 27.92108 30.42802
[[4]]
[1] 44.11469 41.45602 37.20356 46.58535 36.47634IMPORTANTE, tutte le liste incluse devono avere la stessa dimensione!
mapply
mapply(function(x,y) rnorm(n = 4, mean = x, sd = y), medie, stds, SIMPLIFY = FALSE)
function(...): è una funzione anonima come abbiamo visto prima che può avere n elementirnorm(n = 10, mean = x, sd = y): è l’effettiva funzione anonima dove abbiamo i placeholders x and ymedie, stds: sono in ordine le liste corrispondenti ai placeholders indicati, quindi x = medie e y = stdsSIMPLIFY = FALSE: semplicemente dice di restituire una lista e non cercare (come sapply) di semplificare il risultato
mapply come for
Lo stesso risultato (in modo più verboso) si ottiene con un for usando più volte l’iteratore i:
medie = list(10, 20, 30)
stds = list(1,2,3)
res = vector(mode = "list", length = length(medie)) # lista vuota
for(i in 1:length(medie)){
res[[i]] = rnorm(n = 6, mean = medie[[i]], sd = stds[[i]])
}
res[[1]]
[1] 9.270645 10.245305 11.041807 9.675548 11.544734 8.298364
[[2]]
[1] 17.87364 21.64267 17.72736 18.85137 18.62249 18.69013
[[3]]
[1] 29.18226 32.01760 32.85111 33.73556 35.73785 24.22059replicate
Questa funzione permette di ripetere un operazione n volte, senza però utilizzare un iteratore o un placeholder.
replicate(n, expr)
nè il numero di ripetizioniexprè la porzione di codice da ripetere
replicate
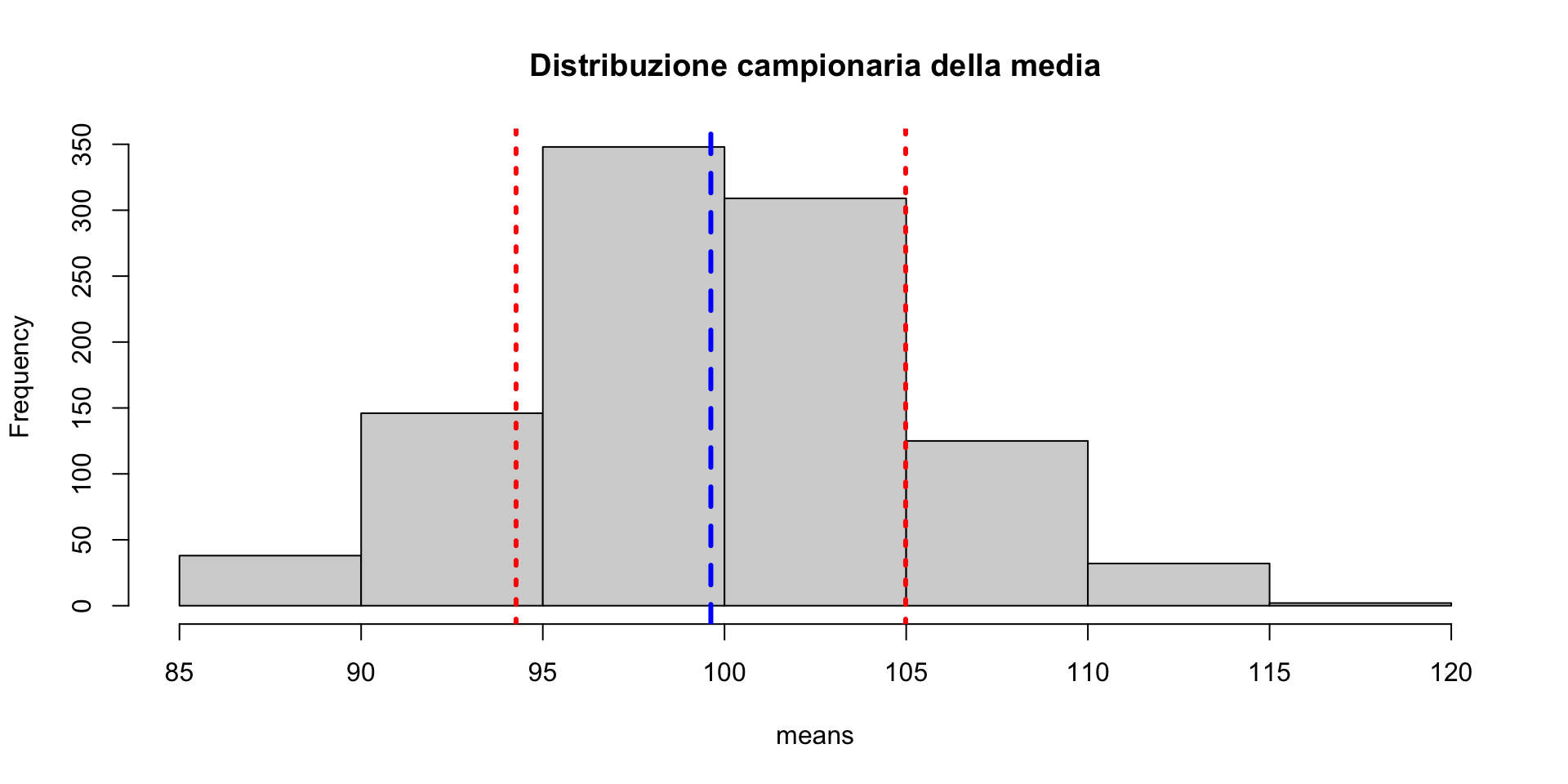
Campioniamo 1000 volte da una normale e facciamo la media AKA distribuzione campionaria della media
Ora facciamo un po’ di pratica!
Aprite e tenete aperto questo link: